*edit: classification report 오류 수정 (06/09/22)
오늘은 퇴사 예측 모델을 만들어 볼 계획이다. EDA과정을 충분히 거치고 진행하면 더 좋겠지만 우선 아주 러프하게 모델만 돌려보도록 하자.
사용할 데이터는 IBM에서 배포한 Attirition 데이터, 캐글에서 가장 유명한 데이터다!
총 1470 (명) X 35 (개의 column)으로 되어있다.


데이터는 간단한 전처리 과정과 필요없는 컬럼을 제거하고 1470 X 31 개만 남겼다.
사용할 모델은 LogisticRegression 로지스틱회귀모델이다. 이름은 회귀이지만 사실 기능적으로 Classifier분류모델 이다. 범주형/연속형 X변수를 통해 Y이진분류를 할 수 있다.
첫번째, 기본(Baseline) 버전.

위는 해당 데이터프레임의 컬럼들을 리스트로 나타낸 것이다.
형광펜 친 Attrition(퇴사여부)를 Y로 두고 나머지는 모두 X로 넣어 모델을 만들었다.

- No. observations전체 자료 수: 2,623
- Df Residuals잔차 자유도: 2,606
- Df Model모델자유도: 16
- Pseudo R-squ. 설명력: 0.3427
로지스틱회귀분석은 선형회귀분석처럼 설명력이 대단히 의미있다고 보지 않는다. 오늘은 유의미한 변수를 찾아 베이스라인 성능을 높이는것이 소기의 목적이므로 모델 정확도 위주로 봐보도록 하겠다.

자, 여기서 더 발전을 해 나가야 하니 변수를 한번 추려보도록 하겠다.
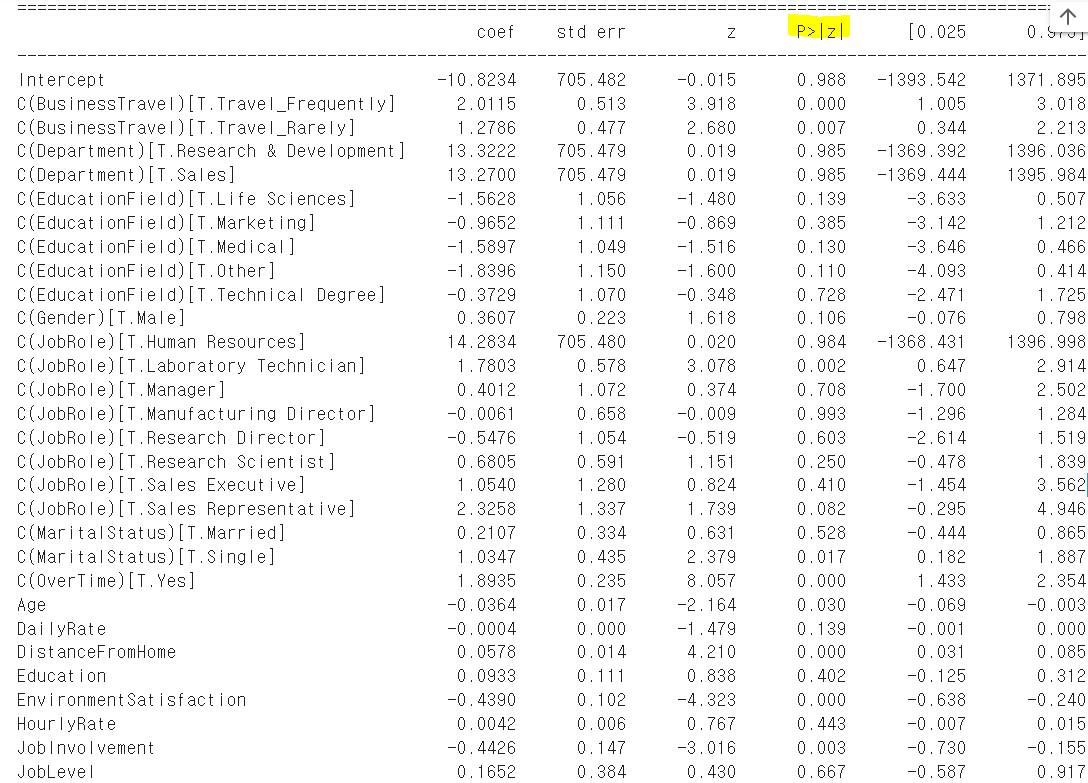
유의수준을 0.05 정도로 잡고 연관성 있는 변수를 추려내보려고 한다.
=실제 연관이 없는데도 불구하고, 실수로 연관성 있다고 나올 리스크가 5% 이하(혹은 그 주변)인 변수 라고 생각하면 된다.
그 결과 Department, Education field, Education, Hourly Rate, Job level, Performancerate 등을 삭제할 수 있었고, 다음과 같이 두 번째 모델을 출력할 수 있었다. JobRole 과 Marital Status 에도 5%이하 범주가 보이나 이부분은 나중에 처리하고 일단 앞에 언급한 컬럼들만 삭제해보도록 하겠다.
두 번째, 변수 일부 삭제 버전

제거 결과, 큰 차이가 없다. 퇴사한 경우에서의 f1-score가 조금 높아지기는 했다.
세 번째, 파생변수 생성 후 적용하기
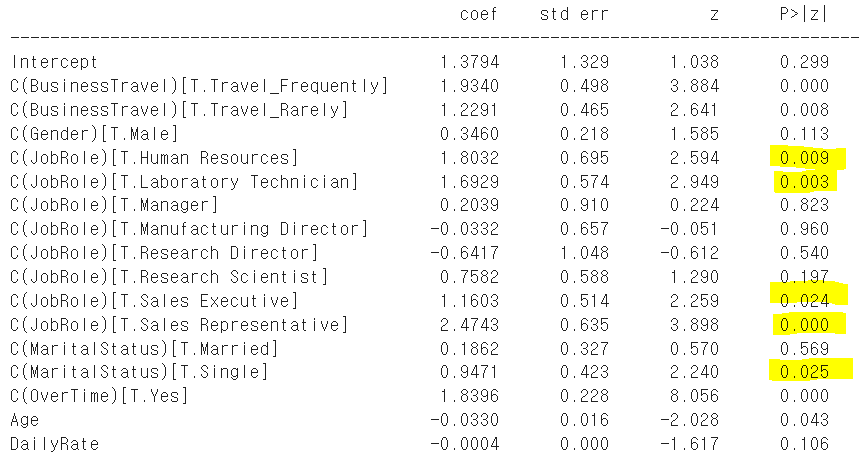
이번에는 데이터를 건드려보도록 하겠다.
JobRole과 MatritalStatus에서 눈에 띄는 범주들이 있다.
1. JobRole
: 1) 인사담당자 2) 실험실 테크니션 3) 세일즈 Executive & 4) 세일즈 Representative 총 네 개의 롤들에서 '퇴사'와 유의미한 관련성이 보인다. 따라서 해당 롤들을 '퇴사하기 쉬운 롤' 이라고 가정한다. JobRole_label이라는 새로운 변수를 만들어 해당 4개의 롤이라면 '1'을, 아니라면 '0'을 부여한다.

자, 그리고 잠시 궁금증을 해결해보도록 하겠다. Sales Representative 와 Sales Executive의 차이이다. Sales가 들어간 두개의 직무가 둘다 퇴사와 관련성이 높다니 궁금하지 않은가? 롤의 차이인지 레벨의 차이인지 (Executive가 때에 따라서 더 윗단계일 수 있을 것 같아서) 모르겠어서 일단 간단히 봐보도록 한다.


해당 집단의 Role의 체계가 어떤지는 모르겠으나 Executive가 Representative보다 수도 많고, 돈도 더 많이 받는다. Representative를 짧게 끝내고 Executive로 넘어가는 시스템인가? 잘 모르겠다^^;
또한, Sales Representative의 p-value가 0.0이었다.. odds ratio를 뽑아서 보면 좋겠지만 이 포스팅에서는 간단히 시각화만 해보도록 하겠다. 한눈에 봐도 Sales Representative의 Attirition수가 non-attrition수에 거의 가깝게 가 있는 것을 확인할 수 있겠다.

자.. 간단한 궁금증을 해결했으니, 다시 본론으로 돌아가서 Marital Status도 라벨링 해보겠다.
2. MatritalStatus

: Single에서 '퇴사'와 유의미한 관련성이 보인다. 따라서 싱글 = 퇴사가 쉬운 상태라고 가정하고 Single_label 변수를 새로 만들어 싱글이라면 1을, 아니면 0을 부여한다.

자, 이렇게 변수를 조정한 뒤 다시 모델을 돌려보도록 하겠다.
그 결과는 아래와 같았다.

다시한번 Baseline과 최종 모델 성능을 비교해보자.

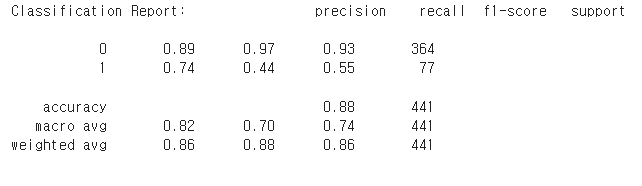
- 88퍼센트의 모델 정확도 (모델이 퇴사할 사람, 퇴사안할사람을 알맞게 맞출 확률)
- 데이터 불균형으로 인해 퇴사자에 대한 특성 학습 부족
- 퇴사한 사람 100명을 놓고 이 기계에게 퇴사여부를 물어보면 100명중 44명에게 퇴사자라는 답을 내림
- 반면 퇴사하지 않은 사람 100명을 놓고 물어보면 97명에게 퇴사하지 않았다는 답을 내림
- 기계가 "이사람 퇴사 안한 사람이에요" 라고 100번 말했다면 이중 89번은 정답
- 기계가 "이사람 퇴사 한 사람이에요"라고 100번 말했다면 이중 74번은 정답
*아래는 본 내용 + 심화 (정확도 올리기) 를 다루는 유튜브 동영상입니다.
궁금하신 분들은 전체 과정을 확인해 보세요~!
'재미난 공부들 > People Analytics 공부 기록' 카테고리의 다른 글
| AI인터뷰 - 사용자 경험(Candidate Experience)의 연계 (1) | 2023.06.06 |
|---|---|
| [AIHR] Global Data Integrity 글로벌 데이터의 정확성/일관성 관리 (0) | 2022.07.06 |
| [논문 읽기] 조직 내 '뇌과학적' 다양성 확립 Building a Neurodiverse Workforce (0) | 2022.05.29 |
| 회귀분석 Regression, HR에서의 활용 예시 (0) | 2022.04.19 |
| 유럽 정보 보호 기준(2018) 의 HR 적용 방안 (0) | 2022.04.15 |