*실제로 밸런스가 깨진 데이터의 성능을 설명할 시 f1-score만 비교해주면 됩니다.
멘토링 시, 초심자 분들 께서는 Precision과 Recall을 많이 궁금해 하셔서 그부분을 상세하게 설명할 예정입니다.
*confusion matrix를 이해하고 계신 분들은
3. 무엇을 읽을 수 있는가?
부터 보시면 됩니다.
0. 맥락 이해하기
- 어떤 사람 Index데이터를 주면, AI알고리즘이 이 사람이 채용에 적합한지 부적합한지 (즉, 합격인지 탈락인지) 판단하는 이진 분류 알고리즘을 개발하려고 함.
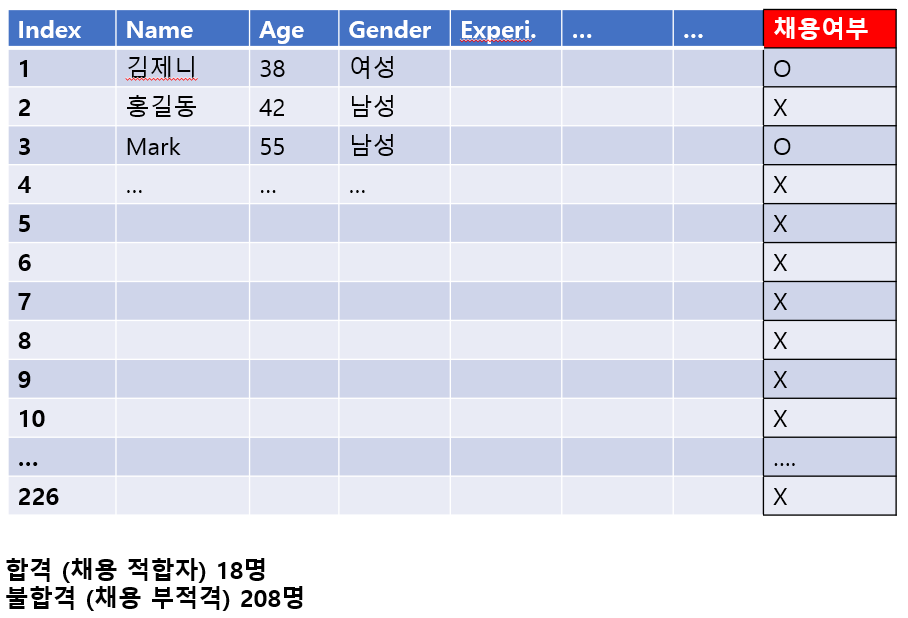
- 총 약 300명의 기존 채용 결과 데이터가 있으며, 이중 226명 데이터를 Train데이터로, 나머지를 Test데이터로 사용하여 알고리즘을 학습시키고 모델의 성능을 검증하려고 함.
- 성능 검증을 왜 하나? 부적격자를 적격자로, 적격자를 부적격자로 잘못 판별하는 일이 많으면 이 모델을 의사결정에 쓸 수 없기 때문에 이러한 오작동이 어느정도 일어나는지 판단해야 함.
- 아래의 Classification Report는 train 데이터셋 학습 결과에 대한 성능 평가로서, 이 기계의 학습데이터에 대한 이해도를 나타냄. (일반화 능력 즉 test data 에 대한 성능 검증도 실시하나 이 포스팅에서는 따로 report로 뽑아 보지 않음. 같은 방식으로 진행하면 됨)
- 상상이 안되시는 분들을 위해 아래에 train 데이터셋을 간단히 시각화하여 첨부.

이 데이터셋에서의 '채용 여부' 를 정답으로 생각하면 됨.
숙련된 면접관들이 다양한 각도로 후보자를 평가한 뒤 채용을 결정했던 데이터 이기에, 여기에 채용 되었다고 적혀있다면 실제로도 해당 포지션 적임자라는 것을 전제로 포스팅을 풀어보겠음.
1. Confusion Matrix (혼돈 행렬) 이해하기
키워드: Accuracy, Recall, Precision, f1-score

- 2 X 2 의 4가지 케이스가 있을 것임.
1) 실제로 합격(적임자) 이고 기계도 합격자로 분류한 경우 (정답 맞춤)
2) 실제로 합격(적임자) 이지만 기계는 불합격자로 분류한 경우 (오작동)- 적임자를 탈락시켜버림
3) 실제로 불합격(부적격자) 이고 기계도 불합격자로 분류한 경우 (정답 맞춤)
4) 실제로 불합격(부적격자) 이지만 기계는 합격자로 분류한 경우 (오작동)- 채용해서는 안될 후보자를 합격시켜버림
2), 4) 처럼 기계가 잘못 판단을 내리면 HR 관리 측면에서 비용이 커짐을 생각하면서 하나씩 해석해 보도록 함.
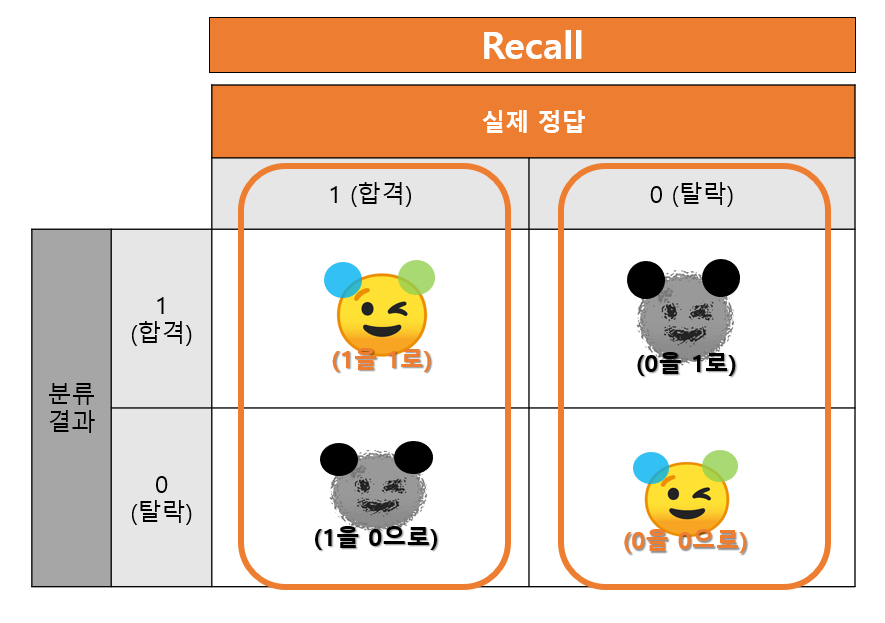
키워드1. Recall - 실제 정답 기준
핵심: Recall 은 (실제 정답) 이 합격이냐 아니냐에 기준을 두고 그 기준에 따라 정답을 맞춘 확률을 말함
위의 그림을 바탕으로 Recall 1만 하나 구해보자면, 아래와 같을 것임.

같은 방식으로 Recall 0은 "실제로 적임자가 아닌 상황에서 기계 역시 불합이라고 말할 확률"일 것임
키워드2. Precision - 분류 결과 기준
Precision 은 (분류 결과) 가 합격이냐 아니냐에 기준을 두고 그 기준에 따라 정답을 맞춘 확률을 말함

위와 같은 방식으로 각각 Precision1 즉 "기계가 합격이라고 말한 상황 중 정말로 해당 후보자가 적임자일 확률" 과 Precision0 즉 "기계가 탈락이라고 말한 상황 중 정말로 해당 후보자가 적임자가 아닐 확률" 을 알 수 있음.
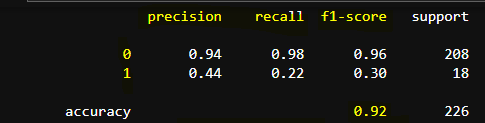
2. Classification Report 확인하기
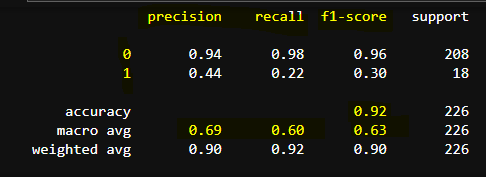
채용 여부 관련 데이터 226 개를 train 데이터로 선정하여, Decision Tree Classifier 모델에 학습시키고 classification_report()로 출력한 결과임.
위 그림과 함께 생각하면서 실제로 어떻게 해석될 수 있는지 보겠음.
각 항목 별로 아래에 오작동할 경우를 두껍게 표시했음.

1.Recall 0 (0.96)
(실제) 적임자가 아니며 / 탈락자라고 잘 (분류)한 확률: 96%
(실제) 적임자가 아닌데 / 합격이라고 잘못 (분류)한 확률: 4%
즉, 합격시키면 안되는 사람을 합격시켜버린 확률 4%
2. Recall 1 (0.72)
(실제) 적임자이며 / 합격이라고 잘 (분류)한 확률: 72%
(실제) 적임자임에도 / 탈락이라고 잘못 (분류)한 확률: 38%
합격 시켜야하는 사람을 탈락시킬 확률: 38%
3. Precision 0 (0.98)
탈락이라고 (분류) 했는데 / (실제)로도 적임자가 아닐 확률: 98%
탈락이라고 (분류) 했는데 / (실제)로는 적임자였을 확률: 2%
합격 시켜야 하는 후보자를 탈락시킨 확률: 2%
4. Precision 1 (0.59)
합격이라고 (분류) 했는데 / (실제)로 적임자일 확률: 59%
합격이라고 (분류) 했는데 / (실제)로는 적임자가 아닐 확률: 41%
합격시키면 안되는 사람을 합격시킬 확률: 41%
3. 무엇을 읽을 수 있는가?
1. Precision1, Recall1 에서 각각 합격 시켜야 하는 사람을 탈락시킨 확률: 38%, 합격시키면 안될 사람을 합격시켜버린 확률: 41% 이 나와서 오류가 많다는 걸 알 수 있었음.
즉, 이 모델은 불합격자(0)에요! 라고는 자신 있게 말할 수 있는데,
합격자(1)에요! 라고는 자신 있게 말할 수 없는 것.
채용할 사람을 떨어뜨리고 채용해서는 안될 사람을 합격시켜버리면 HR은 관리 측면에서 손해가 막심할 것임.
따라서 이 모델을 쓸 수 있을까 라는 의문이 듦. 좋은 모델이 아닌 것 같음.
2. 그런데 Accuracy는 높다? (Accuracy 정의는 아래 그림 참고)

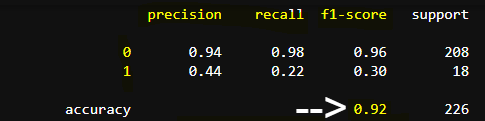
Accuracy가 94%로 나와있어서 언뜻 보면 좋은 모델로 보이지만 위에서 말한것처럼 성능이 별로인 것임.
따라서 Accuracy만 가지고 모델의 성능을 평가하면 안된다는 것을 알 수 있음.
3. 왜 이런 것일까?
데이터가 불균형하기 때문임. 불합격자(208명) 데이터에 비해 합격자(18명) 데이터가 적어서, 합격자 특성에 대한 학습이 충분히 이루어지지 않음.
4. 위에까지 이해하고 classification report 를 다시 보면, 0(불합격) 보다 1(합격) 데이터를 다루는 데 있어 성능이 떨어지는 것을 볼 수 있음.
5. 실제 이진분류를 위한 데이터들(공정데이터에서의 불량/양품 분류 등) 은 거의 비율이 깨져있을텐데, 그럼 어떻게 모델을 만드나라는 의문이 들 수 있음.
그런 불균형 데이터의 데이터 밸런스를 맞춰줄 수 있는 다양한 방법이 있음.
(Threshold Tuning/Smote기법 등 아주아주 다양)
마치며
f1-score는 precision/recall을 바탕으로 도출된 하나의 지표 (둘의 조화평균)이며, 대표적인 모델 성능 확인 지표입니다. 따라서 대개 f1-score만 보며 성능비교를 하지, precision과 recall을 이렇게 상세히 해석 하지는 않습니다. 그래도 본 포스팅을 보시고 Recall 과 Precision 이 실제 상황에서 어떤 의미를 가지는지 아실 수 있다면 좋겠습니다~!
'재미난 공부들 > 세미나 및 교육 기록' 카테고리의 다른 글
| 기업 공시 데이터 (재무데이터) 분석을 위한 dart-fss 패키지 (0) | 2023.02.06 |
|---|---|
| [이스트소프트 AI Plus 2021] 간단 후기 (0) | 2021.10.06 |
| [원티드 Live: 데이터로 보는 인사 이야기] 후기 + 기록 (0) | 2021.10.01 |
| [멘토링] 반도체 인공지능 역량 강화교육 (0) | 2021.08.20 |
| [Data Robot 세미나] AI와 비판적 사고: 아마존 AI 인터뷰 폐지 3 (0) | 2020.12.01 |